アーキテクチャおよび内部構造
ゼロ知識コプロセッサ(ZKコプロセッサ)のアーキテクチャは、オフチェーンで計算処理を行いながらも、暗号技術によってオンチェーンシステムと堅固に連携するという、その特有の役割を示しています。本モジュールでは、ZKコプロセッサのシステム構成、システム内でのデータと計算の流れ、そして信頼不要の検証を可能にする暗号学的プリミティブについて詳しく解説します。こうしたアーキテクチャの理解は、コプロセッサの自社アプリケーションへの統合を目指す開発者はもちろん、その信頼性やセキュリティを評価するアナリストにとっても極めて重要です。
ZKコプロセッサのコアコンポーネント
ZKコプロセッサは、計算処理のオフロードと検証性の維持を両立するために、複数の基本要素で構成されています。中核となるのが実行環境であり、多くの場合、ゼロ知識仮想マシン(zkVM)やドメイン特化型回路コンパイラとして実装されます。この環境は、コードや計算タスクを解釈し、ゼロ知識証明生成に適した算術回路へと変換します。
プロバーは計算を実行し、暗号証明を作成する役割を担います。入力データの取得後、必要なロジックをオフチェーンで処理し、計算内容を秘匿したまま正当性のみを示す簡潔な証明を構築します。ベリファイアは、通常ターゲットブロックチェーン上で稼働するスマートコントラクトであり、最小限のリソースでこの証明の検証を実施します。設計上、検証は元の計算処理と比較して極めて軽量となり、オンチェーンでの効率的なバリデーションを実現します。
また、データインターフェースも重要な構成要素です。これは、コプロセッサがさまざまな情報源からデータを取得・アクセスする手段を提供します。あるコプロセッサはオンチェーンデータを直接参照し、他のものは分散ストレージネットワークやオフチェーンAPIなどの外部・過去データセットを収集します。こうしたデータの整合性は、Merkle証明や同種の暗号コミットメントなどにより証明可能である必要があります。
計算フロー
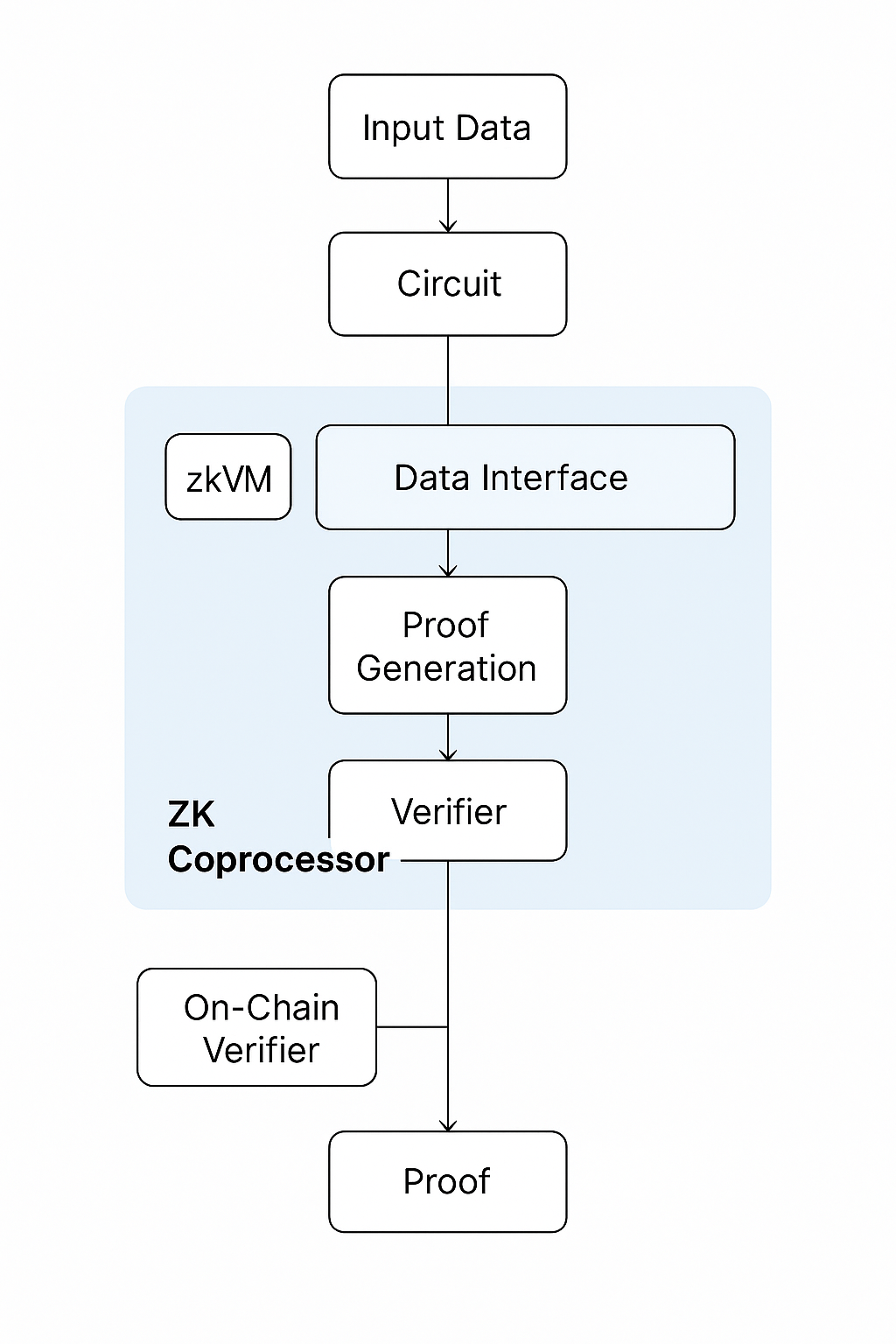
ZKコプロセッサは、重い計算処理と軽量な検証処理を明確に分離したシーケンスで構成されます。まず、分散型アプリケーションやスマートコントラクトが、オンチェーンでは実行が困難な計算処理を要求します。この要求がコプロセッサに送付されると、コプロセッサはブロックチェーンの状態、外部データフィード、ユーザー提供データなどから必要な入力を取得します。
入力を収集後、コプロセッサは自身のzkVMまたは回路環境内で計算処理を実行します。この際、計算タスクは体系化された算術回路に変換され、ゼロ知識証明の生成が可能となります。この証明は、全ての実行過程を要約し、計算の再実行を必要とせずに内容を検証できる仕様になっています。
証明生成後、それはブロックチェーンに返送されます。ベリファイアとなるスマートコントラクトが、公開された検証鍵を活用して証明を検証します。証明が正当と判断されれば、計算結果が承認され、オンチェーンの状態更新やスマートコントラクトの実行、さらに次の分散プロセスへの入力として利用されます。この一連のフローにより、効率性を損なうことなく計算の整合性が堅持されます。
証明生成技術
証明生成は、ZKコプロセッサのアーキテクチャで最も計算負荷が高い工程です。ここでは多項式コミットメントやマルチスカラ乗算といった先端暗号技術が活用され、計算内容が代数的制約集合に変換されます。これら制約を解くことで、簡潔な証明が生み出されます。
近年のシステムでは、このプロセスを複数の手法で最適化しています。高速フーリエ変換(FFT)や数論変換(NTT)は、多項式演算の高速化に用いられ、zk-SNARKやzk-STARKの根幹技術となっています。再帰も、証明を入れ子状に構成可能な技術として普及してきています。再帰的証明によって、膨大な計算を複数の小規模証明に分割し、それらを集約して単一の簡潔な検証につなげることができます。
こうした最適化は、ZKコプロセッサを実用規模へスケールさせる上で欠かせません。最適化施策がなければ、証明生成の速度や資源消費が障壁となり、オフチェーン計算のメリットが損なわれてしまいます。
オンチェーン検証
検証フェーズはターゲットとなるブロックチェーン上で実行され、計算コストを極小化するように設計されています。コプロセッサが証明を提出すると、ベリファイアコントラクトが事前算出済みパラメータを使って検証アルゴリズムを実行します。zk-SNARKを用いる場合、これは一定時間で完了するペアリング検証であり、zk-STARKではハッシュ型コミットメントやFRI(Fast Reed-Solomon Interactive Oracle Proofs of Proximity)プロトコルがベースとなります。
ゼロ知識証明の簡潔性により、検証はわずか数キロバイト程度のデータで済み、同等のオンチェーン計算と比較して消費ガスもごく僅かです。この高効率によって、ZKコプロセッサは本番環境でも十分活用可能な技術となります。証明は計算の正当性だけでなく、入力データの整合性や結果の決定性も同時に確認します。
セキュリティモデルと脅威
ZKコプロセッサのセキュリティは、暗号アルゴリズムの堅牢性とシステム設計の両面に根拠を持ちます。暗号面では、楕円曲線ペアリングやハッシュベースコミットメントなど基礎的難問への依存が不可欠となり、これらが安全であれば証明の偽造は困難です。
一方で、コプロセッサの実装方法やデータ取得の仕組みに脆弱性が混入するリスクもあります。悪意あるプロバーが回路制約を無効化したり、不正なデータで計算を偽装したりするケースが想定されます。この問題に対応するため、コプロセッサは公開入力コミットメントやMerkleルート、信頼されたデータフィードによる正当性証明を活用しています。また、回路の独立監査や形式手法による厳格な検証も、設計ミスの防止に不可欠です。
加えて、システム全体としては可用性やライブネスも考慮する必要があります。コプロセッサが中央集権的だったり、単一の運用主体に依存している場合、運用上の信頼仮定や検閲リスクが増大します。こうした課題解決のため、最近ではコプロセッサネットワークの分散化が進められており、複数のプロバーが証明生成を協調・競争することで、単一主体への依存度を引き下げています。
関連コース

暗号資産におけるアイデンティティ:主なプロジェクト
暗号資産におけるアイデンティティ:主なプロジェクト

マスターノードトークンの紹介
マスターノードトークンの紹介

分散型アイデンティティの基礎
分散型アイデンティティの基礎

オラクルトークンの概要
オラクルトークンの概要

暗号デリバティブ:主なプロジェクト
暗号デリバティブ:主なプロジェクト
